LatticeCast
Next-Gen AI-Native PM System
Design Journey, Architecture Tradeoffs & Lessons Learned
How we designed a project management system where AI is a first-class collaborator, not just a tool.
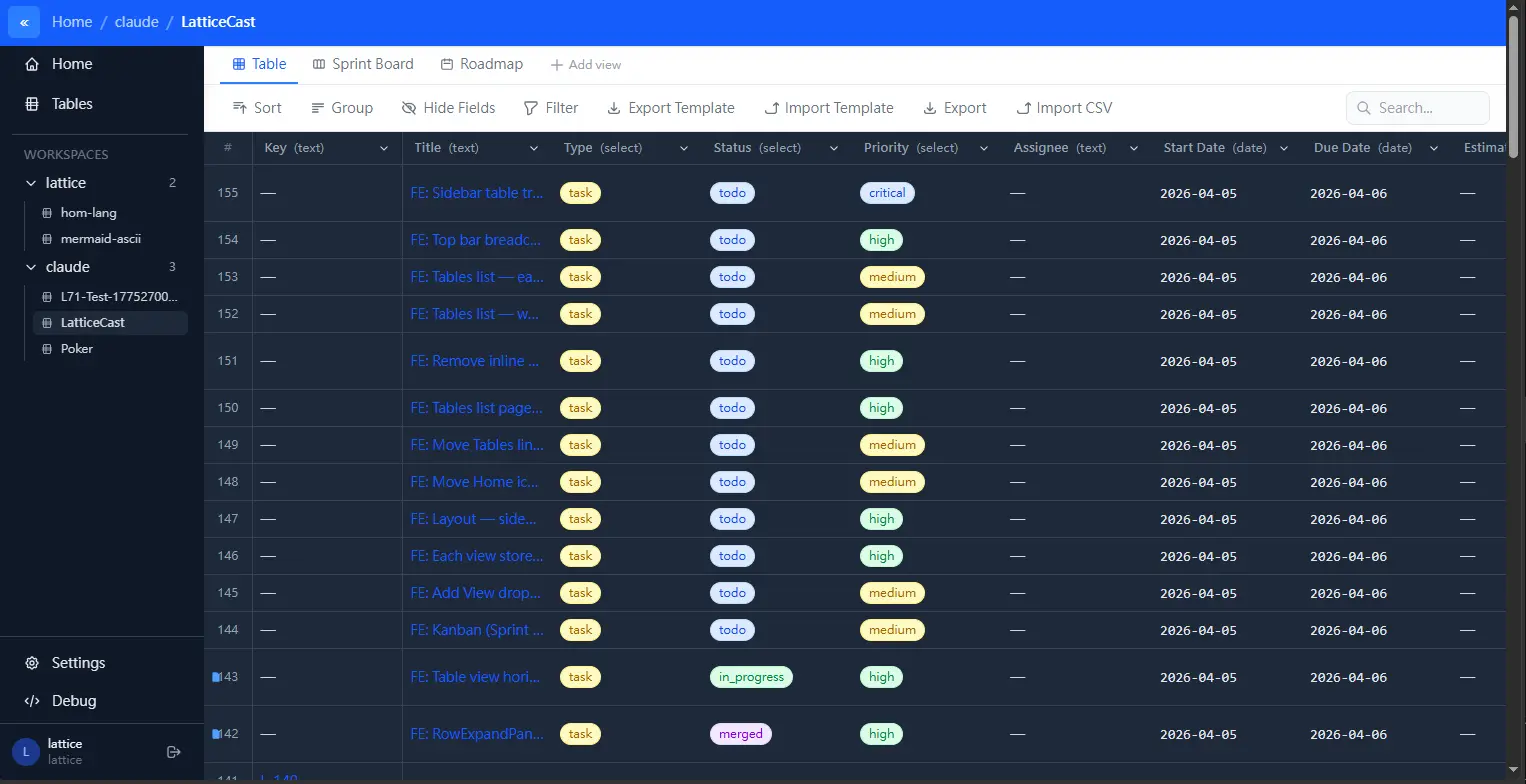
Table View
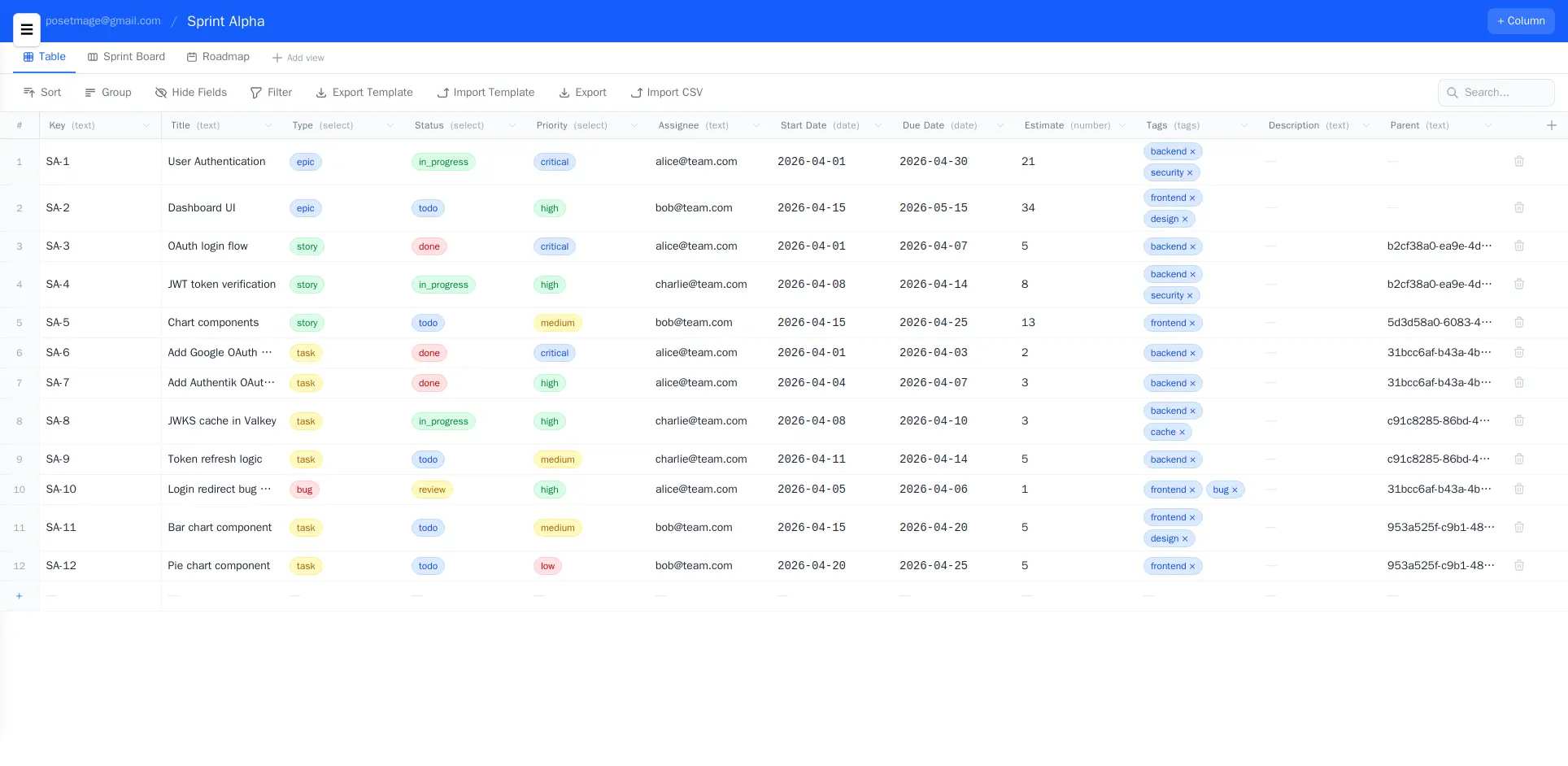
Kanban View
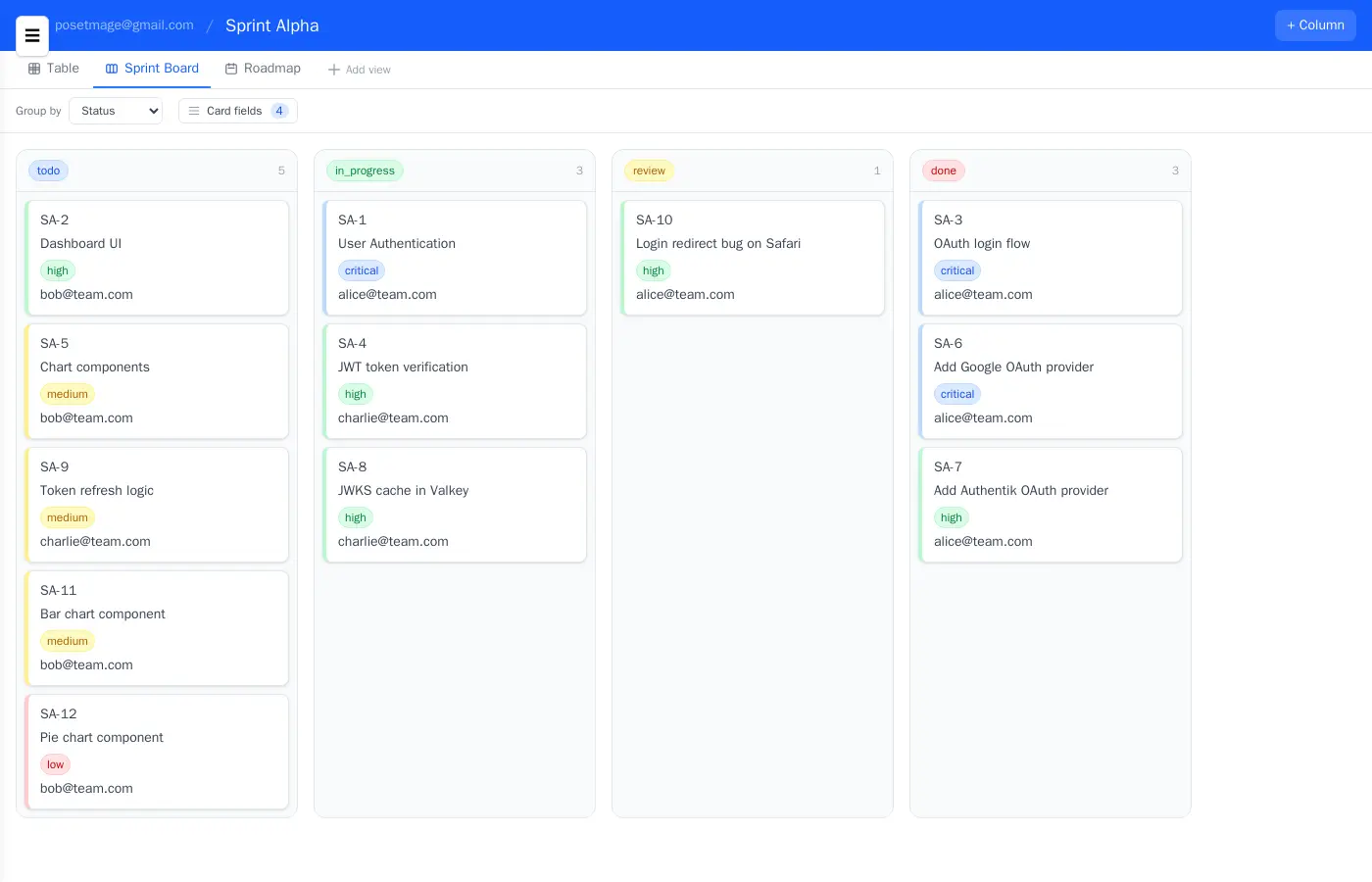
Timeline View
About This Talk
What we will cover in 60 minutes:
- The origin — how a DIY AI dev loop exposed the need
- The PM landscape — what exists and what’s missing
- Why AI-native PM?
- The design evolution — 4 architecture pivots
- Deep dive: JSONB + GIN vs Dynamic DDL vs Template
- How open-source Airtable alternatives actually work
- PostgreSQL myths we busted along the way
- The AI collaboration workflow that changes everything
- Where we landed and why
It Started with a Hack: claude-bot v1
Before designing any PM system, I built something crude but functional:
An autonomous multi-agent dev loop using Claude Code in tmux.
tmux session
├── window 0: orchestrator (Haiku) — reads plan, assigns tickets
├── window 1: worker #1 (Sonnet) — picks ticket, codes, tests, commits
├── window 2: worker #2 (Sonnet) — picks ticket, codes, tests, commits
└── ...N workers
The entire “project management” was a markdown checkbox file. No database. No UI. Just text files.
claude-bot v1: The Markdown Era
The “ticket system” was a plain markdown file:
## Phase 1: Core
- [x] Initialize project scaffold
- [ ] Add database models ← worker picks this
- [ ] Create API endpoints
Workers read the file, pick the first unchecked ticket, implement it, run tests, commit, and check the box.
This worked — but didn’t scale. So we evolved it.
claude-bot v2: LatticeCast PM as SSOT
Replaced markdown checkboxes with a real PM system (the one we built):
tmux session
├── window 0: orchestrator (Haiku) — queries PM API, assigns tickets
├── window 1: worker #1 (Sonnet) — git worktree, codes, tests, merges
├── window 2: worker #2 (Sonnet) — git worktree, codes, tests, merges
└── ...N workers
Key difference: LatticeCast PM is the single source of truth, not text files.
| v1 (Markdown) | v2 (LatticeCast PM) |
|---|---|
.tmp/llm.plan.status checkboxes |
HTTP API ticket queries |
| Done / Not done | todo → in_progress → testing → review → merged |
| Workers edit same file | Workers call PM API to update status |
| No isolation | Git worktree per worker — zero conflicts |
| No history | Full ticket history in database |
claude-bot v2: Worker Lifecycle
Each worker runs in an isolated git worktree:
1. Query PM API → pick first `todo` ticket
2. git worktree add .tmp/worker_{id} -b ticket/{slug}
3. PM status → in_progress
4. Implement the ticket (one ticket only, stay in scope)
5. PM status → testing → run tests
├── pass → PM status → review → commit
└── fail → PM status → debugging → fix → re-test
6. Merge branch back to main, remove worktree
7. PM status → merged
8. Signal DONE to orchestrator
15 min timeout per ticket. If stuck after 3 attempts → BLOCKED.
claude-bot v2: The Planning Phase
Before running, there’s an interactive planning session:
You: "I want a REST API for a blog platform"
Claude (Tech Lead):
→ Reads project structure
→ Proposes architecture
→ Asks clarifying questions
→ Breaks work into <15 min tickets
→ Creates tickets in LatticeCast PM via API
→ "Ready to start?"
You: "Go"
→ Autonomous execution begins
Each ticket must be: independently testable, independently committable, completable in under 15 minutes.
claude-bot: What v1 Taught Us
It works. AI can autonomously pick tickets, write code, test, and commit.
But markdown checkboxes were painfully limited:
- No hierarchy — flat list only, no Epic → Story → Task
- No status beyond done/not-done — no “in progress”, “in review”, “blocked”
- No views — no kanban, no timeline, no filtering
-
No persistence —
.tmp/files are ephemeral, no history - No git integration — workers commit, but there’s no branch → ticket mapping
v2 solved all of these — but first we had to build the PM system.
The Realization
claude-bot v1 proved the concept:
AI can be a productive team member — if the PM system speaks its language.
But markdown checkboxes don’t scale. I need:
- A real database for tickets (not
.tmp/text files) - API-first design (not filesystem coordination)
- Git integration that auto-updates status (not manual checkboxes)
- Views for humans (kanban, timeline) AND API for AI
- Design specs that both humans and AI can read
This is why I started designing a proper PM system.
From Hack to System: The Journey
claude-bot v1 (markdown checkboxes in .tmp/)
↓ "this works but doesn't scale"
↓
PM System Design (pm/core.md, pm/view.md)
↓ "should this be a standalone tool or part of a platform?"
↓
LatticeCast (Airtable-like platform, JSONB + GIN)
↓ "wait, is JSONB the right choice?"
↓
Architecture deep dive (Dynamic DDL? Template?)
↓ "what do we actually need?"
↓
Final answer: Fullstack template + AI writes standard code
↓
claude-bot v2 (LatticeCast PM API + git worktrees)
↓ "now AI has a real PM system to work with"
Each step taught us something. Let’s walk through the decisions.
The PM Landscape: What I’ve Used
| Tool | Used For | Verdict |
|---|---|---|
| Redmine | Classic project tracking | Best timeline/Gantt view in the industry |
| Jira | Enterprise agile | Epic → Story → Task works. Heavy, slow |
| Azure DevOps | Microsoft ecosystem | Decent boards, locked to Azure |
| Asana | Team task management | Clean UI, weak hierarchy |
| Notion | Docs + light PM | Cannot do multi-level hierarchy properly |
| Linear | Modern dev teams | Fast, opinionated, no self-host |
| Airtable | Flexible schemas | Great UI, but no git integration |
| GitHub Projects | Code-linked PM | My longest-used tool — tight code integration |
Redmine: The Gantt Chart King
What Redmine gets right:
- Best timeline/Gantt view — still unmatched after 15+ years
- Parent/child task hierarchy with progress rollup
- Customizable issue types and workflows
- Self-hosted, open source (GPL)
What Redmine gets wrong:
- UI feels stuck in 2008
- Ruby on Rails — hard to extend for modern needs
- No real API-first design
- Plugin ecosystem is aging
Jira: The Enterprise Standard
What Jira gets right:
- Epic → Story → Task hierarchy actually works
- Powerful JQL query language
- Extensive workflow customization
- Marketplace with thousands of plugins
What Jira gets wrong:
- Slow, bloated UI
- Cloud-first now (Server edition discontinued)
- Configuration complexity — “Jira admin” is a full-time job
- API exists but designed for integrations, not AI co-work
- Expensive at scale
Notion: Beautiful but Limited
What Notion gets right:
- Beautiful, flexible documents
- Database views (table, kanban, calendar, gallery)
- Linked databases and relations
What Notion gets wrong:
- Cannot do Epic → Story → Issue multi-level hierarchy
- Sub-pages are documents, not queryable records
- Search is weak — can’t find nested sub-items reliably
- No git integration
- API is read-heavy, not designed for AI to create and manage
- No self-host option
Linear: Fast but Opinionated
What Linear gets right:
- Blazing fast UI — sets the standard for modern PM UX
- Cycles and projects are well-designed
- Good keyboard shortcuts and CLI
What Linear gets wrong:
- Very opinionated workflow — limited customization
- No self-host
- Closed source
- API exists but limited scope
GitHub Projects: My Go-To (Until Now)
Why I used it the longest:
- Tight integration with code — PRs, issues, branches all linked
- Free for open source
- GraphQL API is powerful
- Automation rules (when PR merged → move to Done)
Why I’m moving on:
- Views are GUI-only — no way to define views via API/config
- Custom fields are limited
- No timeline/Gantt view
- Hierarchy is flat (no Epic → Story → Task)
- GitHub controls the roadmap — you can’t extend it
The Common Problem Across All Tools
Every tool assumes a human is doing the work:
- GUI-first design — APIs are afterthoughts
- Status updates require human clicks
- Specs live in one place, code in another
- AI integration = “add a chatbot sidebar”
None of them are designed for AI to be a first-class team member.
What I Actually Need
- API-first — every operation available via REST/GraphQL, not just GUI
- Multi-level hierarchy — Epic → Story → Task (like Jira, unlike Notion)
- Git integration — branch/commit auto-updates status (like GitHub Projects, but better)
- Timeline/Gantt view — proper one (like Redmine)
- Flexible schemas — custom fields per project (like Airtable)
- AI as collaborator — AI reads specs, writes code, updates tickets
- Self-hosted, open source (MIT-like) — own my data, extend freely
- Standard stack — no exotic tech, AI can understand and modify the codebase
No existing tool checks all these boxes. So we build it.
The Problem Restated
It’s not just “PM tools don’t support AI.”
It’s that the architecture of every existing tool prevents deep AI integration:
- GUI-first → AI can’t efficiently operate
- Specs separate from tickets → AI needs to cross-reference
- Status requires human input → no automation loop
- Closed source or complex plugin APIs → can’t customize for AI workflows
What if the PM system was designed from day one for AI to read specs, write code, and auto-update status?
The Vision
A system where:
- Tickets are code specs — stored as markdown in the git repo
- Branches auto-update ticket status — no manual status changes
- AI reads the spec, writes the code, commits with ticket key
- The PM system detects the commit and closes the ticket
Human creates ticket → spec generated in git repo
→ AI reads spec → AI writes code → AI commits with ticket key
→ System detects commit → status auto-updates
→ Human reviews and accepts
Design Spec as SSOT
Each ticket maps to a design doc in the git repo:
---
ticket: PM-123
type: story
parent: PM-100
api_endpoints: [POST /api/auth/login]
---
# PM-123: Implement User Login API
## Acceptance Criteria
- [ ] email + password login
- [ ] return JWT access + refresh token
## API Contract
POST /api/auth/login
Request: { "email": "string", "password": "string" }
Response: { "access_token": "string" }
One file serves both PM and AI. No duplication. No sync issues.
Architecture Pivot 1: The Airtable Approach
Our first instinct: build an Airtable-like system.
- Users create custom tables with flexible schemas
- All row data stored as PostgreSQL JSONB
- GIN indexes for fast filtering
- PM system is one use case on this generic platform
CREATE TABLE rows (
id UUID PRIMARY KEY,
table_id UUID REFERENCES tables(id),
data JSONB NOT NULL DEFAULT '{}',
-- {"col_status_id": "done", "col_priority_id": 3}
);
CREATE INDEX idx_rows_data ON rows USING GIN (data);
Why JSONB? The Appeal
Zero-cost schema changes:
- Add column → old rows just don’t have that key (null)
- Delete column → old rows have an extra key (ignored)
- Rename column → change metadata only, row data untouched
- Change column type → frontend swaps renderer, data stays
No ALTER TABLE. No migrations. No backfill.
This felt perfect for a flexible PM system.
Deep Dive: How GIN Index Actually Works
A common misconception: GIN indexes a single JSON document internally.
Reality: GIN builds an inverted index across ALL rows.
row_1 data = {"status": "done", "priority": 42}
row_2 data = {"status": "todo", "priority": 7}
row_3 data = {"status": "done", "priority": 99}
GIN Inverted Index:
──────────────────────────────────
"status"="done" → row_1, row_3 ← direct lookup!
"status"="todo" → row_2
"priority"=42 → row_1
"priority"=7 → row_2
"priority"=99 → row_3
GIN: What It Can and Cannot Do
| Operation | Uses GIN? | Example |
|---|---|---|
Containment @>
|
Yes | data @> '{"status":"done"}' |
Key exists ?
|
Yes | data ? 'due_date' |
Multi-key exists ?&
|
Yes | data ?& array['a','b'] |
Text search ILIKE
|
No | data->>'title' ILIKE '%login%' |
Range query > <
|
No | (data->>'priority')::int > 3 |
Sorting ORDER BY
|
No | ORDER BY data->>'due_date' |
GIN only helps with equality containment checks. Range queries, text search, and sorting all require sequential scans or expression indexes.
The Server-Side Query Problem
Our frontend was doing ALL filtering, sorting, and searching client-side.
// Frontend: ~50 lines of derived state
const sortedRows = $derived(() => {
let result = $rows; // ALL rows loaded
// filter in browser...
// sort in browser...
// search in browser...
return result;
});
For a PM system with thousands of tickets, this doesn’t scale.
Moving this to the backend with JSONB requires type-aware SQL generation:
-- Number sort needs cast
ORDER BY (data->>'col_priority')::numeric
-- Date range needs cast
WHERE (data->>'col_due_date')::date > '2026-01-01'
-- Each column type = different SQL
The jq Idea (and Why It Fails)
“What if we just pull all rows and filter with jq on the backend?”
Client ←→ Backend (jq filter) ←→ PostgreSQL (SELECT * everything)
↑
bottleneck here
- Every request loads ALL rows into Python memory
- 100 concurrent users = 100 copies of all data in memory
- Pagination becomes meaningless (fetch all, then slice)
- You’re paying for PostgreSQL but using it as a dumb file store
This defeats the entire purpose of having a database with indexes.
The “One Giant JSON Per Year” Idea
Another thought: store all tasks for one year in a single JSONB row.
This reinvents MongoDB — badly.
| Problem | Impact |
|---|---|
| Update one task | Read entire JSON → modify → write entire JSON back |
| Concurrent edits | Lost update: User B overwrites User A’s changes |
| MVCC | Changing any task creates a full copy of the entire document |
| WAL/Backup | One task change = entire year’s data in WAL |
| GIN index | Can only tell you “this one row has a match” — then what? |
PostgreSQL JSONB is designed for one document per row, not one giant document containing all your data.
Questioning Our Assumptions
At this point, we asked: is JSONB really the right choice?
What about Dynamic DDL — creating real PostgreSQL tables when users define schemas?
-- User creates "tickets" table in the UI
CREATE TABLE ut__<uuid> (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
created_at TIMESTAMPTZ DEFAULT now()
);
-- User adds "status" column
ALTER TABLE ut__<uuid> ADD COLUMN c__<uuid> VARCHAR;
-- User adds "priority" column
ALTER TABLE ut__<uuid> ADD COLUMN c__<uuid> INTEGER;
The ALTER TABLE Myth
We initially rejected Dynamic DDL because:
“ALTER TABLE takes an AccessExclusiveLock and rewrites the entire table!”
This is wrong for modern PostgreSQL (11+, released 2018).
| Operation | Speed | Rewrites Table? |
|---|---|---|
ADD COLUMN |
Instant | No — catalog only |
ADD COLUMN DEFAULT x |
Instant (PG 11+) | No — catalog only |
DROP COLUMN |
Instant | No — marks as deleted |
RENAME COLUMN |
Instant | No — catalog only |
ALTER COLUMN TYPE |
Slow | Yes — rewrites all rows |
ADD NOT NULL constraint |
Slow | No, but full scan to verify |
Adding and removing columns is O(1) in modern PostgreSQL. The performance argument against Dynamic DDL doesn’t hold.
How PG 11+ ADD COLUMN Works
Before PG 11:
ADD COLUMN priority INT DEFAULT 0
→ Rewrite every row to add the new column with default value
→ Locks entire table during rewrite
→ O(n) where n = number of rows
After PG 11:
ADD COLUMN priority INT DEFAULT 0
→ Store default value in system catalog
→ When reading a row that doesn't have this column:
→ Return the catalog default automatically
→ O(1) always
This is the same behavior as JSONB returning null for missing keys — but with native types and indexes.
How Open-Source Airtable Alternatives Work
We surveyed the landscape:
| Project | Storage Strategy | Stack |
|---|---|---|
| NocoDB | Dynamic DDL — real ALTER TABLE | Node.js + Vue |
| Baserow | Dynamic DDL — real PG tables | Django + Vue |
| Teable | Dynamic DDL + PG triggers/views | Next.js + Prisma |
| Undb | SQLite — real tables | SvelteKit + Rust |
| Grist | SQLite per document | Node.js + Python |
Every major open-source alternative uses Dynamic DDL, not JSONB.
Why They All Chose Dynamic DDL
It’s not because GIN was immature — JSONB + GIN has existed since 2014 (PG 9.4).
It’s because their goal is “general-purpose database UI”:
- Users expect to query with standard SQL tools
- BI tools (Metabase, Grafana) need real columns
- Linked records need real foreign keys
- Formulas and rollups need SQL aggregation
- Sorting and filtering work natively — no casting
The requirement drives the architecture, not the technology maturity.
JSONB vs Dynamic DDL: Honest Comparison
| Capability | JSONB | Dynamic DDL |
|---|---|---|
| Add/drop/rename column | Fast | Equally fast (PG 11+) |
| Native SQL queries | Need cast | Direct |
| Native indexes | Expression index | CREATE INDEX |
| FK / Linked records | Not possible | Native |
| BI tool integration | Needs adapter | Direct |
| AI generating SQL | Must know JSONB structure | Standard SQL |
| Schema complexity | Simple (fixed tables) | Higher (dynamic table names) |
Architecture Pivot 2: Dynamic DDL
So we should switch to Dynamic DDL like Baserow?
LatticeCast (Airtable-like platform, Dynamic DDL)
├── PM Plugin (task management + git sync)
├── CRM Plugin (customer management)
└── Future plugins...
Each plugin = a table template + custom business logic.
But then we asked a harder question…
The Plugin Architecture Question
If LatticeCast is a platform with plugins:
You → spend months building the platform
→ AI writes plugins on top of the platform
→ PM system, CRM system, etc.
But AI already knows how to write FastAPI + Svelte + PostgreSQL.
Why build an abstraction layer that AI then needs to learn?
Architecture Pivot 3: The Template Approach
Instead of building a platform:
You → spend days preparing a fullstack template
→ AI directly writes PM system (standard PG tables)
→ AI directly writes CRM system (standard PG tables)
AI doesn’t need a no-code platform. AI needs a clean starting point.
lattice-cast/
template/
├── docker-compose.yml # PG + Valkey + MinIO
├── backend/ # FastAPI skeleton + auth
├── frontend/ # SvelteKit skeleton + auth
├── k8s/ # Deployment manifests
└── CLAUDE.md # AI development guide
CLAUDE.md: The AI’s Development Guide
The most important file in the template:
# Tech Stack
- Backend: FastAPI + Python 3.12 + async SQLAlchemy
- Frontend: SvelteKit 2 + Svelte 5 + Tailwind 4
- Database: PostgreSQL 18
# How to Add a Feature
1. Write migration: backend/migration/003_xxx.sql
2. Add model: backend/src/models/xxx.py
3. Add router: backend/src/router/api/xxx.py
4. Register in main.py
5. Add frontend page + API client
AI reads this, then generates standard code. No plugin API to learn.
Template vs Platform: The Tradeoff
| Platform (Airtable-like) | Template + AI | |
|---|---|---|
| Time to first PM system | Months (build platform first) | Days |
| AI’s learning curve | Must learn plugin API | Zero (standard stack) |
| Code quality | Constrained by abstraction | Native, optimal |
| Flexibility | Limited to platform capabilities | Unlimited |
| Shared infrastructure | Built-in (auth, storage, UI) | Duplicated per project |
| Non-technical users | Can use it | Cannot |
Architecture Pivot 4: The Final Realization
PM and CRM are not plugins of a platform.
They are independent systems built from the same template.
lattice-cast (template)
│
├── AI generates → PM System
│ ├── Standard PG tables (tickets, epics, sprints)
│ ├── Git sync logic
│ ├── Design spec integration
│ └── AI collaboration workflow
│
└── AI generates → CRM System
├── Standard PG tables (customers, deals, activities)
├── Pipeline management
└── Customer-specific logic
The AI Collaboration Workflow
This is the core differentiator — from pm/core.md:
1. Human creates ticket in PM system
2. System generates docs/designs/PM-123.md in git repo
3. Human fills in acceptance criteria and API contract
4. AI reads the spec file
5. AI writes code, commits with ticket key
6. PM system runs git fetch, detects commit
7. Branch exists → status auto-updates to "in progress"
8. Branch merged → status auto-updates to "merged"
9. Human reviews and manually sets "done"
The ticket IS the spec. The spec IS the AI’s input. The commit IS the status update.
Git Integration: The State Machine
Git sync detects 3 states automatically. Everything else is manual.
pending → in_progress → merged → sit → uat → done
↓ ↓
fixing ←──── fixing
↓
merged (re-merge after fix)
| State | Detected By | Meaning |
|---|---|---|
pending |
No matching branch | Not started |
in_progress |
Branch exists in git branch -r
|
Developer working |
merged |
Branch in git branch -r --merged main
|
Code merged |
sit / uat / done
|
Manual only | Testing & acceptance |
Key rule: done is always set by a human. The system never auto-closes a ticket.
Branch Pattern Matching
Users define their own branch naming convention:
# Template variables expand to regex
pattern: "${type}/${key}/${desc}"
# Expands to: ^(\w+)/([a-z_]+\d+)/(.+)$
# Examples that match:
feat/lc_42/add_user_profile → key = lc_42
fix/lc_108/login_bug → key = lc_108
Users can also use raw regex:
regex:^feature/([A-Z]+-\d+)-(.+)$
# Matches: feature/PROJ-42-add-thing
Test Status: Script-Driven
Tests are not auto-detected. Scripts report results via API:
# Test pass — only updates test_status
curl -X POST /api/pm/test_status \
-d '{"ticket_key": "lc_42", "test_status": "pass"}'
# Test fail — updates test_status AND sets status to "fixing"
curl -X POST /api/pm/test_status \
-d '{"ticket_key": "lc_42", "test_status": "fail"}'
On failure, the system auto-sets status to fixing. Developer creates a fix branch → git sync detects in_progress → merge → re-test.
The test script can be a CI step, a git hook, or a manual command.
Parent/Children: Ticket Hierarchy
Like Jira’s Epic → Story → Task, but user-defined:
PM-100 User Authentication System (Epic)
├── PM-123 Implement Login API (Story)
│ ├── PM-124 Create login endpoint (Task)
│ ├── PM-125 Implement JWT signing (Task)
│ └── PM-126 Frontend login form (Task)
└── PM-127 Password Reset (Story)
Using a parent_key column — no enforced hierarchy. A solo developer might use a flat list. A team might use 3 levels.
Views: Same Data, Different Rendering
Table View, Kanban Board, and Timeline all read from the same tables:
- Table View — spreadsheet grid, the SSOT for editing
- Kanban — cards grouped by any select field (status, priority, assignee)
- Timeline / Gantt — horizontal bars based on any date field
- Calendar — monthly/weekly view
Switching views doesn’t re-fetch data. All views can edit — writes go back to the same rows.
The Real Use Case
This isn’t theoretical. The system is designed for:
1. Build the PM system using the template + AI
2. Use the PM system + AI to develop an ECS game engine
→ Tickets = engine feature specs
→ AI reads specs, writes engine code
→ Git sync tracks progress
3. Use the PM system + AI to create multiple games
→ Each game = a set of tickets with design specs
→ AI implements game features from specs
4. Use the template + AI to build a CRM system
→ For managing customers/guests
→ Standard PG tables, no JSONB, native performance
Lessons Learned: Architecture Decision Records
| Decision | Initial Choice | Final Choice | Why We Changed |
|---|---|---|---|
| Schema storage | JSONB + GIN | Standard PG tables | GIN only helps @>, not sort/range |
| Schema changes | JSONB (no DDL) | ALTER TABLE |
PG 11+ makes ADD COLUMN instant |
| System design | Airtable platform | Fullstack template | AI doesn’t need no-code |
| Plugin architecture | Plugin API + registry | Independent projects | Less abstraction = more AI capability |
| Query execution | Client-side | Server-side | Thousands of rows need DB-level filtering |
Lessons Learned: PostgreSQL Myths
Myth 1: “ALTER TABLE ADD COLUMN is slow and locks the table”
Reality: Instant since PG 11 (2018). Only updates system catalog.
Myth 2: “JSONB + GIN gives you flexible querying for free”
Reality: GIN only supports containment (@>). Range queries, sorting, and text search still need sequential scans or expression indexes.
Myth 3: “Dynamic DDL is dangerous for user-driven schemas”
Reality: Every successful open-source Airtable alternative uses it. The 1,600 column limit is unlikely to be hit. SQL injection is avoided by using UUID-based names (ut__<uuid>, c__<uuid>).
Lessons Learned: AI-First Design Principles
- Don’t build abstractions for AI — AI already knows standard frameworks
- Specs in git = SSOT — serves both humans and AI
- Standard SQL > JSONB — AI generates better SQL for real tables
- Template > Platform — lower barrier, faster iteration
- Let git be the state machine — branch status is truth
- Manual close only — never let automation mark something as “done”
The Stack
| Layer | Technology | Why |
|---|---|---|
| Frontend | SvelteKit 2 + Svelte 5 + Tailwind 4 | Lightweight, reactive, fast iteration |
| Backend | FastAPI + Python 3.12 + async SQLAlchemy | AI writes Python well, async for git ops |
| Database | PostgreSQL 18 | Standard tables, native types and indexes |
| Cache | Valkey 8 | JWKS cache, view result cache |
| Storage | MinIO (S3-compatible) | File attachments, design assets |
| Auth | Google OAuth + Authentik (PKCE) | SSO-ready, JWKS validation |
| Infra | Docker Compose / K8s | Dev and prod parity |
What We Ship
lattice-cast/
template/
├── docker-compose.yml
├── k8s/
├── backend/
│ ├── src/main.py # FastAPI skeleton
│ ├── src/core/db.py # Async SQLAlchemy
│ ├── src/middleware/auth.py # OAuth (done)
│ ├── src/config/settings.py # Env config (done)
│ └── migration/ # SQL runner (done)
├── frontend/
│ ├── src/lib/UI/ # Button, Input (done)
│ ├── src/lib/auth/ # OAuth flow (done)
│ └── src/routes/ # Login + callback (done)
└── CLAUDE.md # AI dev guide
80% of the infrastructure already exists from the LatticeCast codebase.
The Conversation with AI
Creating a PM system:
You: "Build a PM system with this template. I need:
- tickets table (key, title, status, priority, assignee)
- git sync that reads /repos/ and parses branch names
- kanban view grouped by status
- design spec generator (markdown in git repo)"
AI: Writes migration SQL → models → routes → frontend
All standard FastAPI + Svelte + PostgreSQL
No plugin API to learn
No JSONB to deal with
The Conversation with AI (continued)
Creating a CRM system:
You: "Build a CRM system with this template. I need:
- customers table (name, email, company, stage)
- deals pipeline (amount, probability, close_date)
- activity log (calls, emails, meetings)
- pipeline kanban view"
AI: Writes migration SQL → models → routes → frontend
Different schema, same template
Native PG types, proper indexes
No shared infrastructure conflicts
Debugging Tip: Version Your .claude/skills
When building with Claude Code, skills in .claude/skills/ control AI behavior. But how do you know if Claude actually loaded the latest version?
Add a version field to the YAML frontmatter:
# .claude/skills/pm-workflow/SKILL.md
---
name: pm-workflow
version: 1.3
description: PM ticket creation and git sync workflow
---
## Instructions
...
When something feels off, just ask Claude: “What version of pm-workflow are you using?”
If it says 1.2 but you wrote 1.3 — it’s using a stale cache. Restart the session.
Simple, zero-cost, saves hours of debugging “why isn’t it following my instructions?”
Open Questions
Things still being decided:
- Real-time updates — WebSocket or polling? (Valkey pub/sub)
- Permissions — workspace-level isolation? Row-level security?
- Notifications — email / Slack / in-app?
- Design spec sync — one-way (PM → git) or two-way?
- Multi-user editing — CRDT or last-write-wins?
- Offline support — needed for game dev scenarios?
Key Takeaways
- Challenge your assumptions — our biggest “performance concern” (ALTER TABLE) was a myth
- Survey the landscape — every Airtable alternative had already solved this
- Match architecture to user — if the user is AI, you don’t need no-code
- The spec is the ticket — design docs in git serve both PM and AI
- Let the database be a database — standard PG tables beat JSONB for structured data
- Ship the template, not the platform — get to the actual product faster
What’s Next
Phase 1: Finalize the template (strip LatticeCast to essentials)
Phase 2: Build PM system with AI (first real test)
Phase 3: Use PM system to build ECS game engine with AI
Phase 4: Build CRM system with AI (validate template reuse)
Phase 5: Open source the template
The best project management tool is the one that makes AI a productive team member.
Thank You
Questions?
- Template repo: lattice-cast (coming soon)
- Design docs: pm/core.md, pm/view.md